Mnemosyne fails to find executables in their installation locations on MacOS. Therefore, we need to specify these location in the configuration file first.
I finished reading On Writing Well by William Zinsser. I mentioned in my February notes why I wanted to read this book — people expect you to know how to write, but nobody teaches you how to write. Non-native speakers face greater challenges. Teachers say that the more adjectives and the longer sentences the better. Clichés and standard collocations are what get you an A. But this is not how good English writers write.
The book consists of two parts. The first part gives you tools to improve your writing. It is simple. Use only what’s necessary. Don’t add words to your writing to sound smart. Avoid adding new adverbs when choosing a precise verb would do the same job. Use adjectives only when their meaning is not part of the noun. Keep your writing simple. Write for yourself. Keep it short. Always rewrite. Express your real self because people want to hear the real you. Find precise words for what you want to say.
The second part of the book focuses more on writing different types of prose. It was not immediately beneficial for me now because I did not intend to write something as big as a memoir. But it was inspiring and encouraging. Sometimes I wanted to grab my laptop and write something personal.
I noticed on Goodreads that some reviewers say that Zinsser’s style lacks poetry and imagination. But this is missing the point. This book is not about fictional writing, where vivid descriptions are encouraged. It’s about expressing ideas clearly.
In my entire life, people taught me to do the opposite. Therefore, this approach to writing felt new and refreshing.
The book would likely be called “Lean writing” if it were written today.
I resurrected my blog. I took the idea for these regular posts from Tom MacWright. This is more interesting than posting content to different services like Letterboxd, Goodreads, Twitter, 500px, and so on.
I finished reading Surely You’re Joking Mr. Feynman, which I liked and wrote about.
I wanted to learn how to write better. Almost anyone in your life assumes that you know how to write. But nobody teaches you to write. If you are not a native speaker of English, you learn to do the opposite. Your teachers say that you need to use fancy words, idioms, and collocations to make your writing sound better. This is not how I want to write. I want to write like Paul Graham. My favorite thing about his essays is that I can imagine him talking. So I started reading On Writing Well by William Zinsser, which is a popular book on writing. It focuses on the simple and precise use of the English language for writing non-fiction.
I started the introduction course on reinforcement learning by David Silver. It is ten weeks long. I might finish it sooner, but I prefer spending time on better understanding ideas, so it might take longer. I also started reading Reinforcement Learning: An Introduction, which is a classic book on the subject, and David’s course is partly based on it.
Orville Wright’s first flight on December 17, 1903
The brothers were born in Ohio, a typical part of the United States. They did not have special education and had no investments. Yet, they were hardworking, austere, and detail-oriented. They had a supportive family, where curiosity and the “fix it” mindset were encouraged. They were ordinary people and they showed that ordinary people can accomplish extraordinary things.
McCullough is an excellent writer. He turns history into an interesting story and gives sufficient detail without getting boring.
This book is not only interesting for its insights into the history of aviation and progress, but also because it provides advice on product development. Cheap prototypes and quick iterations — it’s all there.
I liked this book. It was fun to read about how Feynman saw the world. He did not care about what other people thought about him. He kept doing what he liked. Maybe this quality of a character is what it takes to do great things. However you define greatness. Or maybe it is the never ending curiosity. Or finding small things that make the world interesting and worth exploring.
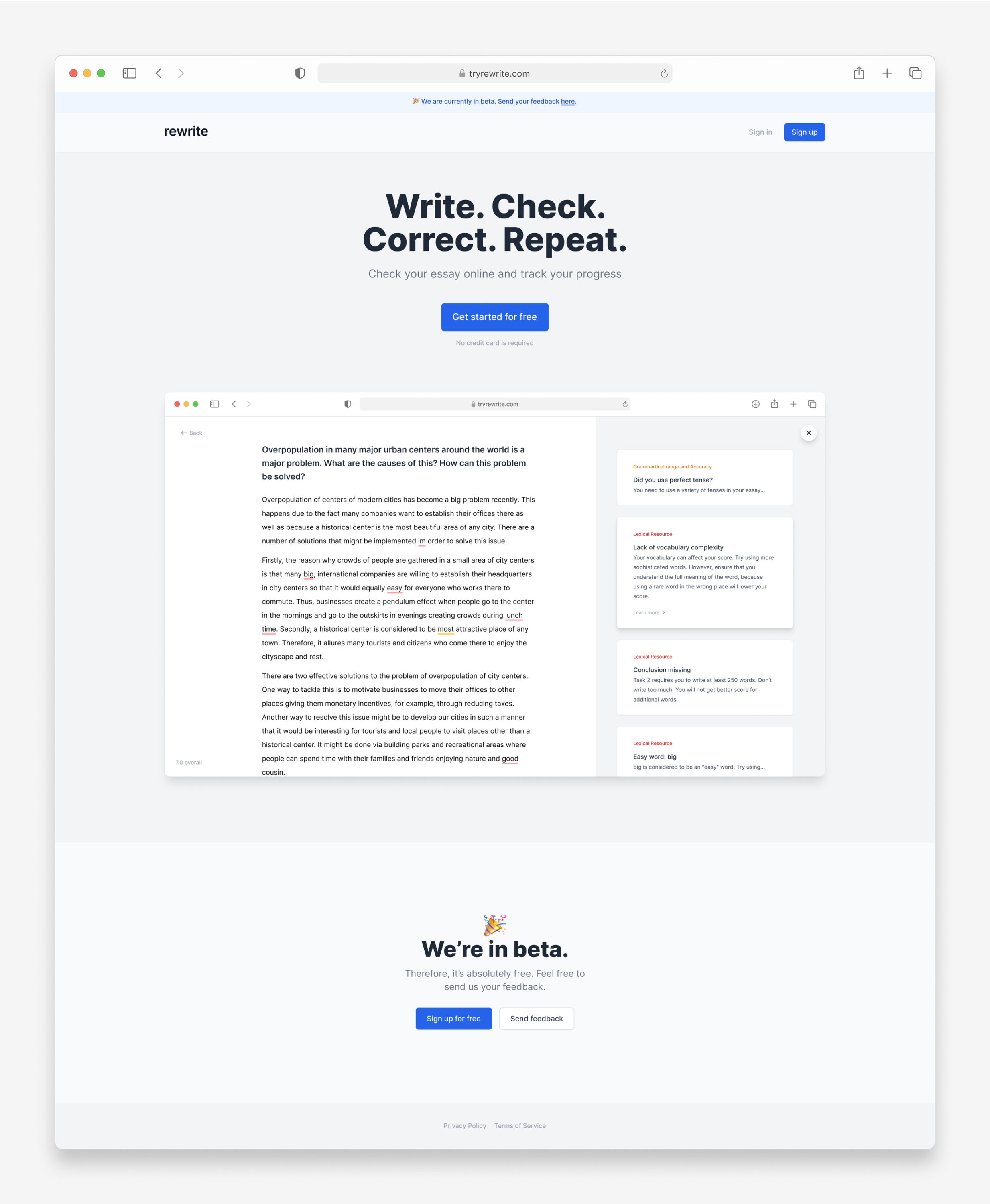
When preparing to the IELTS exam, many people face challenges in the writing section, primarily due to the absence of quick feedback and the need to use multiple tools for essay reviews. I designed and built a web application to address these issues.
Research
My research into the problem included conducting interviews, collecting feedback from teachers, analyzing essays, and reviewing online resources to identify helpful tools and strategies for effective essay writing.
Based on this research, I decided that I would focus on solving the following problems first:
Ensuring that grammar checker is tailored to the exam
Replacing self-checklists with programmatic checks
Providing faster feedback on essays (including approximate score)
Providing some guidance for people who are not familiar with the exam
Explorations
Then I moved to exploring the overall design and core components: navigation, cards, layout, colors and interactions.
I researched similar apps such as online and offline text editors, grammar checkers, online essay checkers, Dribbble, book readers, and apps that allowed leaving comments anywhere.
Research board
Card layout and color exploration
Design
As I worked on the design, I explored a variety of options for different elements of the interface. This was an ongoing process, as I constantly evaluated and refined my choices based on their effectiveness and overall aesthetic.
For a moment, let’s consider the main screen of the app — the editor. It consists of a text area for the essay and a sidebar. Let’s take a look at the sidebar.
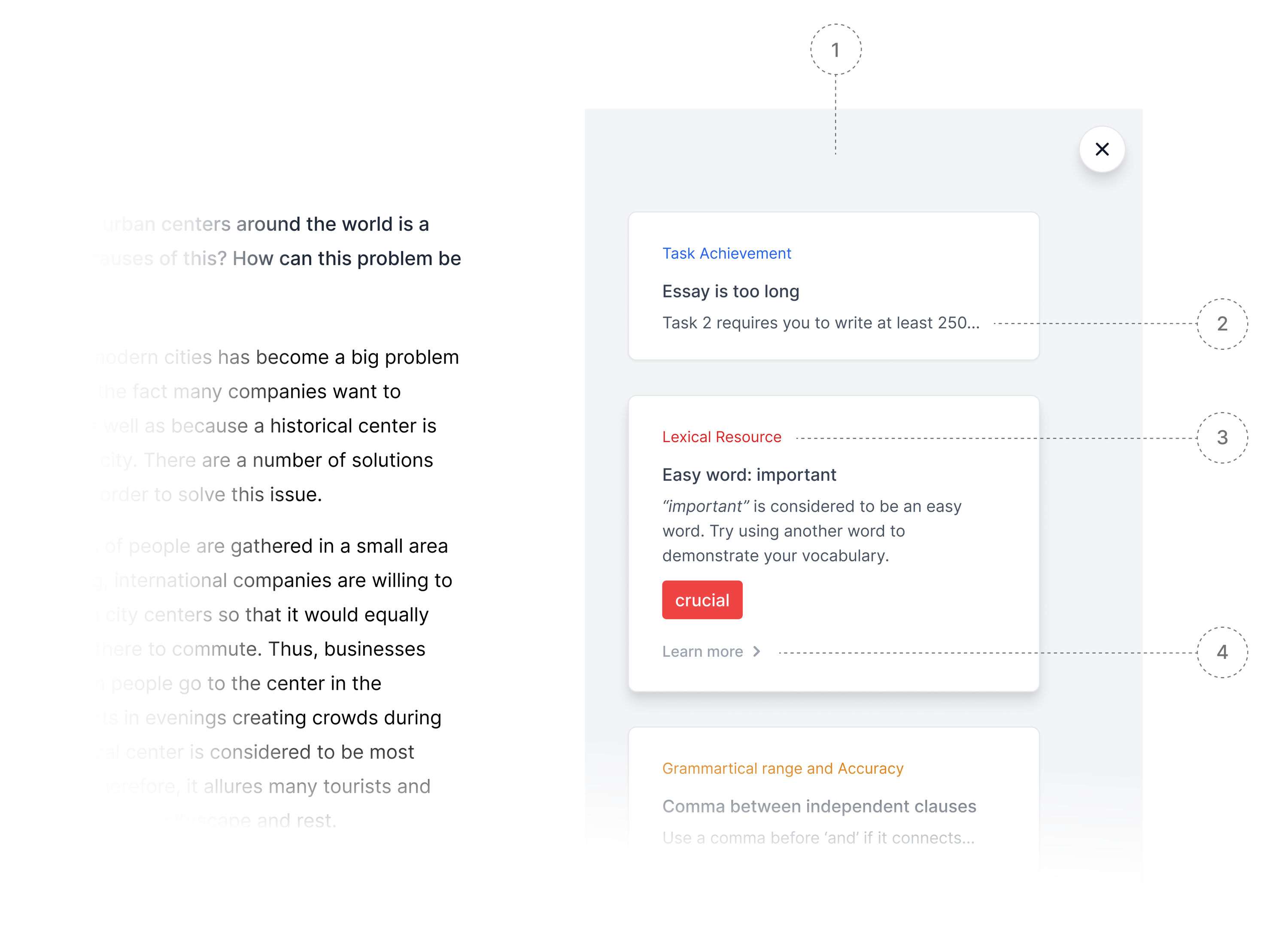
In the sidebar, there is a list of check cards, which were initially shown on a white background. However, after testing this design on a low-resolution monitor, I found that the cards were difficult to see on a white background, and changed the background color to light gray (1).
In the collapsed form, cards only show a header and one line of description (2). This provides more space for other cards and at the same time, the meaning remains clear. Each card is color coded to reflect the exam scoring system (3). Each card can be clicked to expand and show the check results, with the option to include a link to a more detailed explanation of the check (4).
Interactions
One aspect of the UX design that I particularly liked was the way that underlined text interacted with the corresponding check card. Clicking on an underlined check scrolls the sidebar to the related card, and clicking on a check card scrolls the text to the card. This feature helps users easily connect checks with the corresponding text.
Another key feature of the app is the ability to apply suggestions without manually copying them. For instance, when a grammar check produces a suggestion, users can simply click a button to apply it, making the correction process more efficient. This feature enhances the user experience by making it easier and faster to fix mistakes.
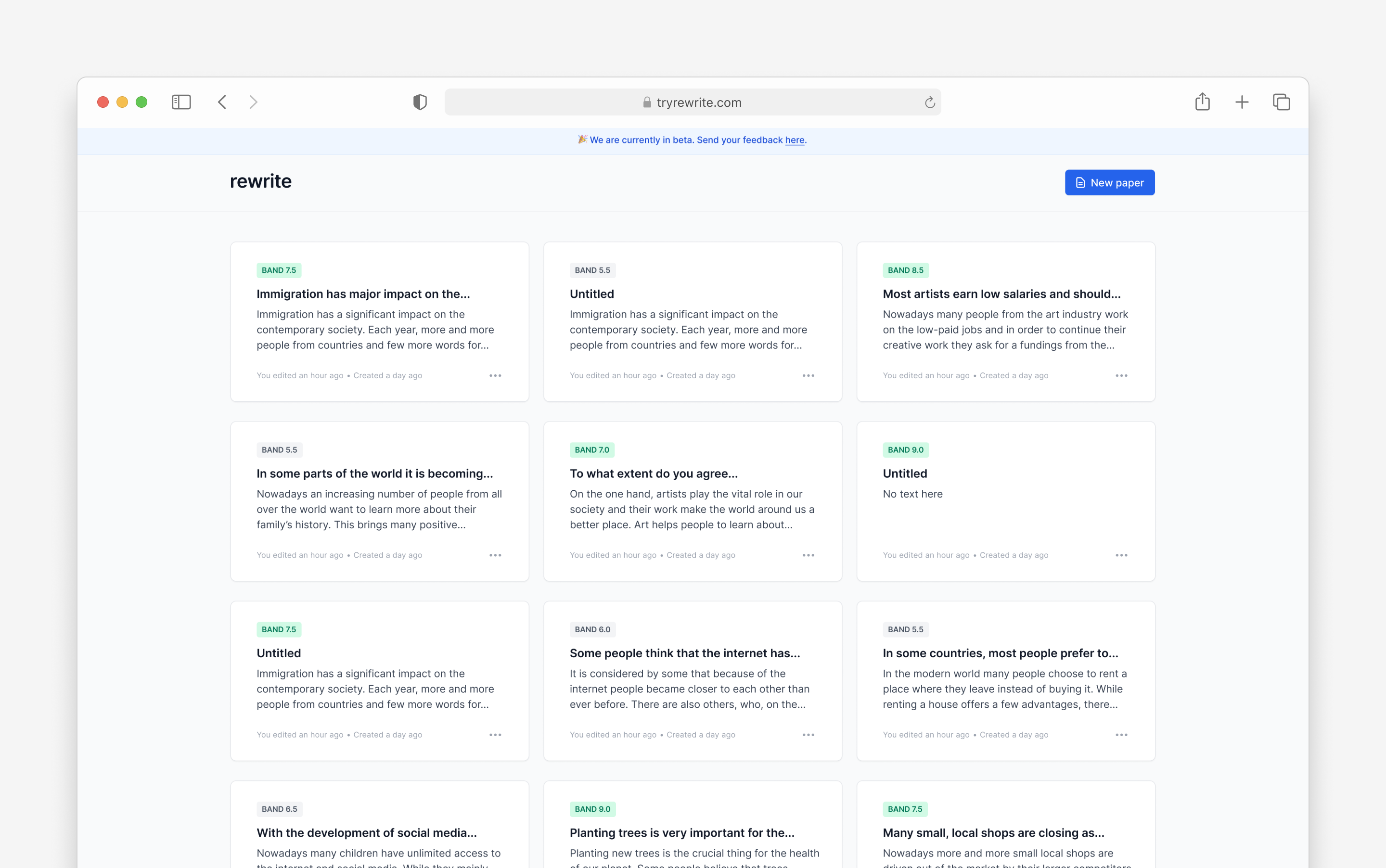
Other screens
Besides the editor, I also designed other app screens, including the sign-in, sign-up, password reset, and dashboard screens, landing page as well as all the transactional emails that the app sends.
I conducted a few more interviews with people to get feedback on the app. People said that the app replaced multiple other tools for them, was clear and easy to use. The main concern was about the reliability of the calculated score. It felt too “mechanic”. Unfortunately, it was the feature that I thought was worth charging for because it saved people time and money. I removed it until I can come up with a more effective solution.
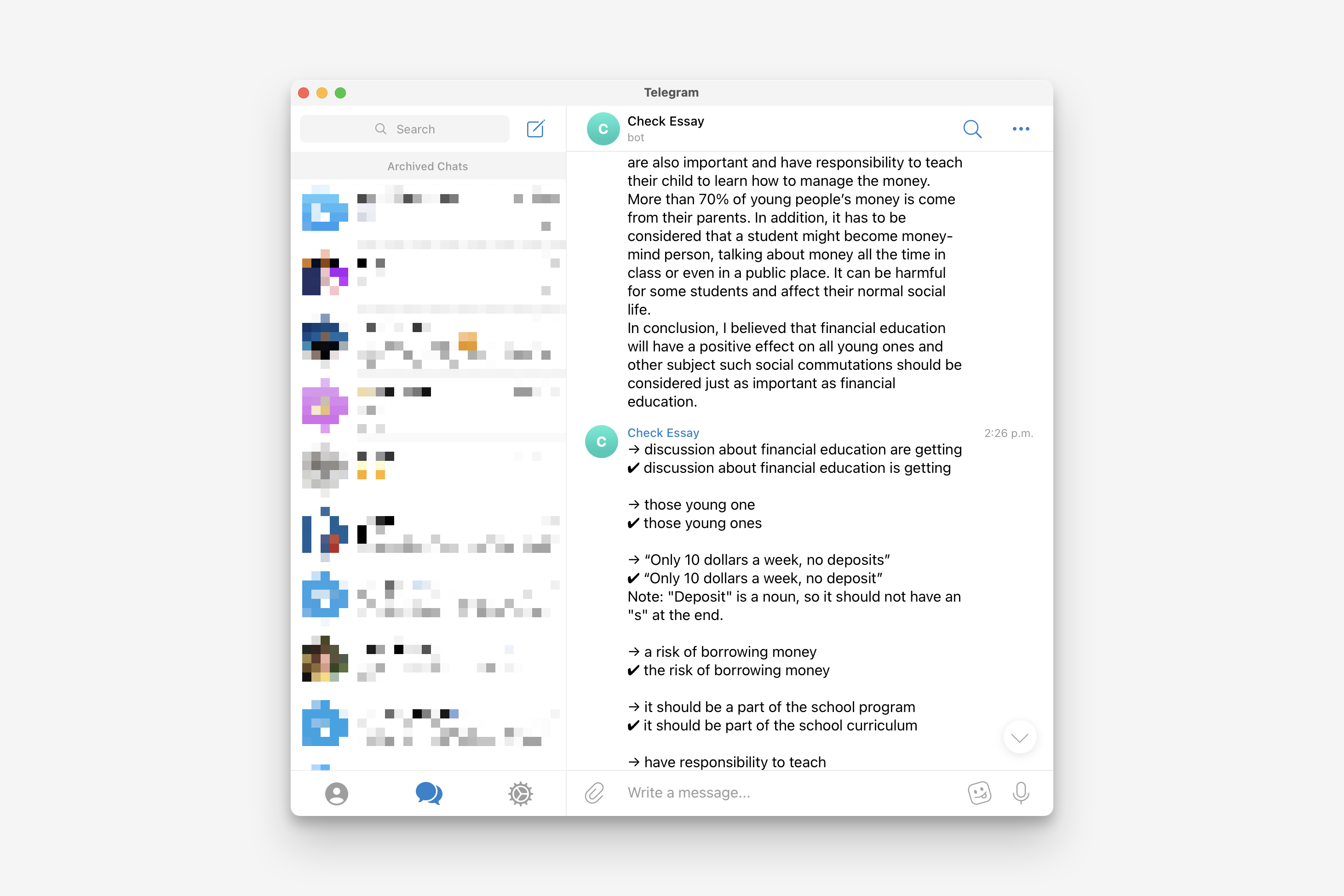
Then, I thought that might leverege LLM for essay scoring. I built a Telegram bot that provided text feedback on essays to validate this idea. The scoring was still not accurate enough, and the API was quite expensive (12 cents per call for a fine-tuned model). Additionally, the training data was very limited, so it’s possible that the exam organizers will implement their own AI-based scoring system in the future, rendering my app obsolete.
Considering all these factors, I decided to stop working on this app.